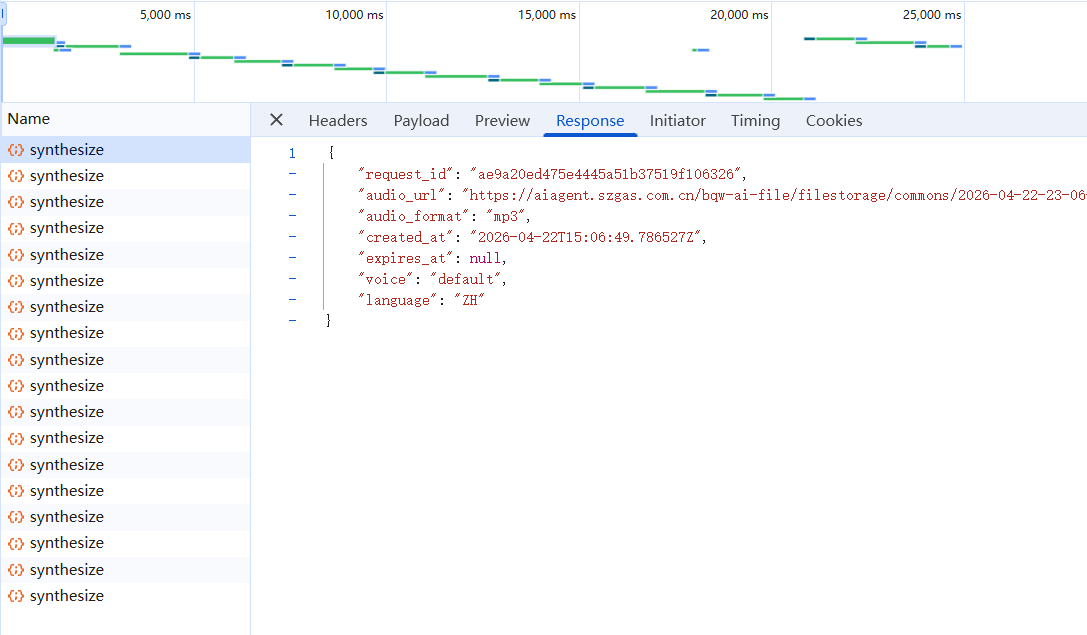
前端负责采集、显示与播放;FastAPI 网关贯穿会话;Dify 负责任务编排;Home Assistant 负责设备实体与服务调用;ASR/TTS 独立为语音节点。
从数据流看,系统可以理解为三条路径在同一会话中交汇:语音上行路径通过 WebSocket 上传 PCM 并返回识别文本;业务控制路径调用外部接口和设备服务;媒体下行路径把文字和音频返回前端。
部署上,将 Dify 和 Home Assistant 放在本地容器中,将语音节点放在局域网单独机器上,分离编排调度和高负载音频计算,减少资源竞争造成的抖动。
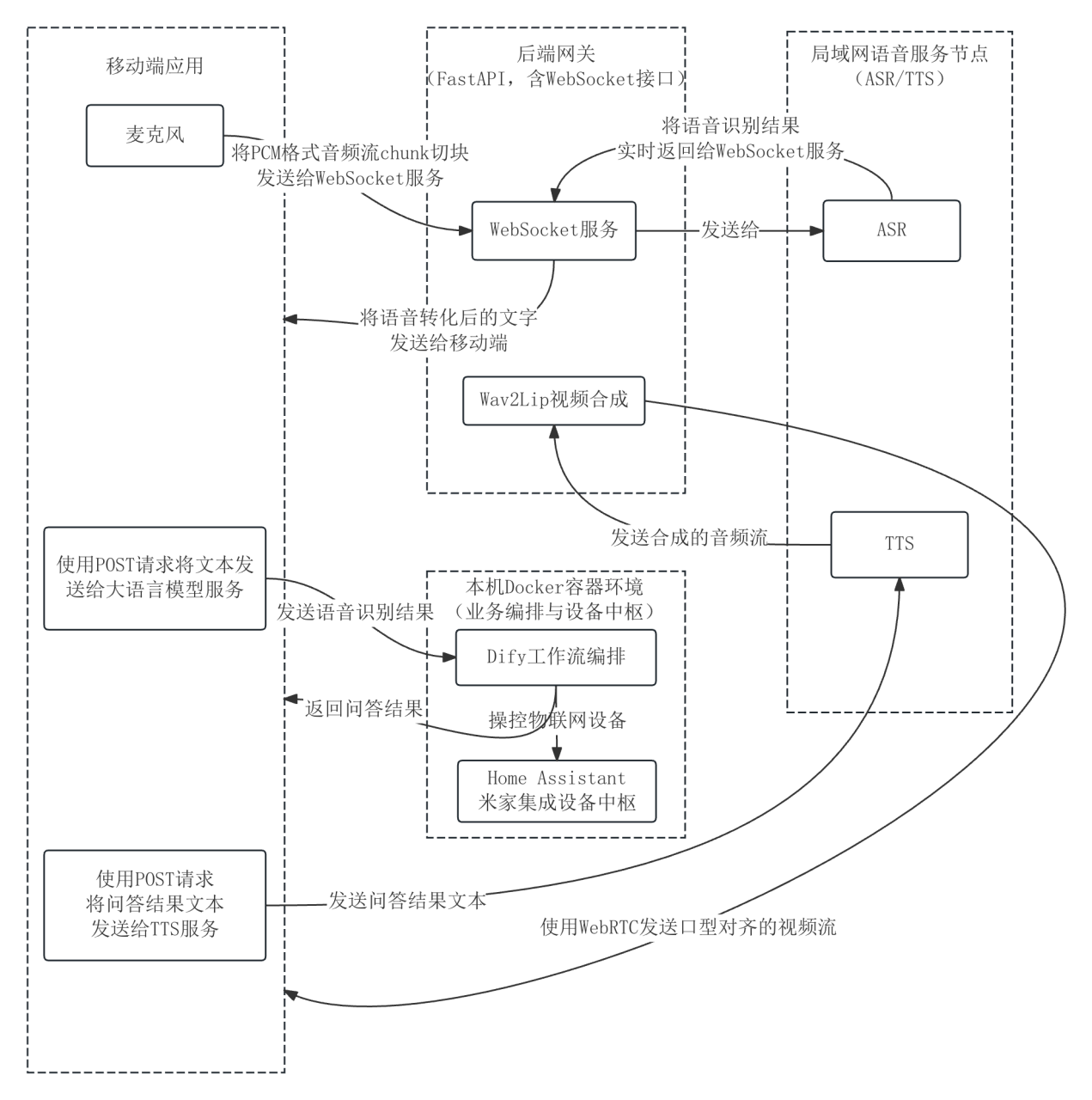
ASR 的实时输出先呈现在界面上,让用户直观看到语音是否被正确转成文字。只有在问题完整后,系统才把最终文本交给 LLM 工作流。
语音处理模块负责把原始声音转化为可用于业务流的文本,过程包括采集、分帧、传输、实时转写和规整。相比一次性上传音频文件,分帧流式可以让用户在讲话时看到正在形成的字幕。
模块边界止步于输出可用识别文本,不在 ASR 阶段进行意图裁决,这样可以把识别错误和分支误判区分开,便于后续定位问题。
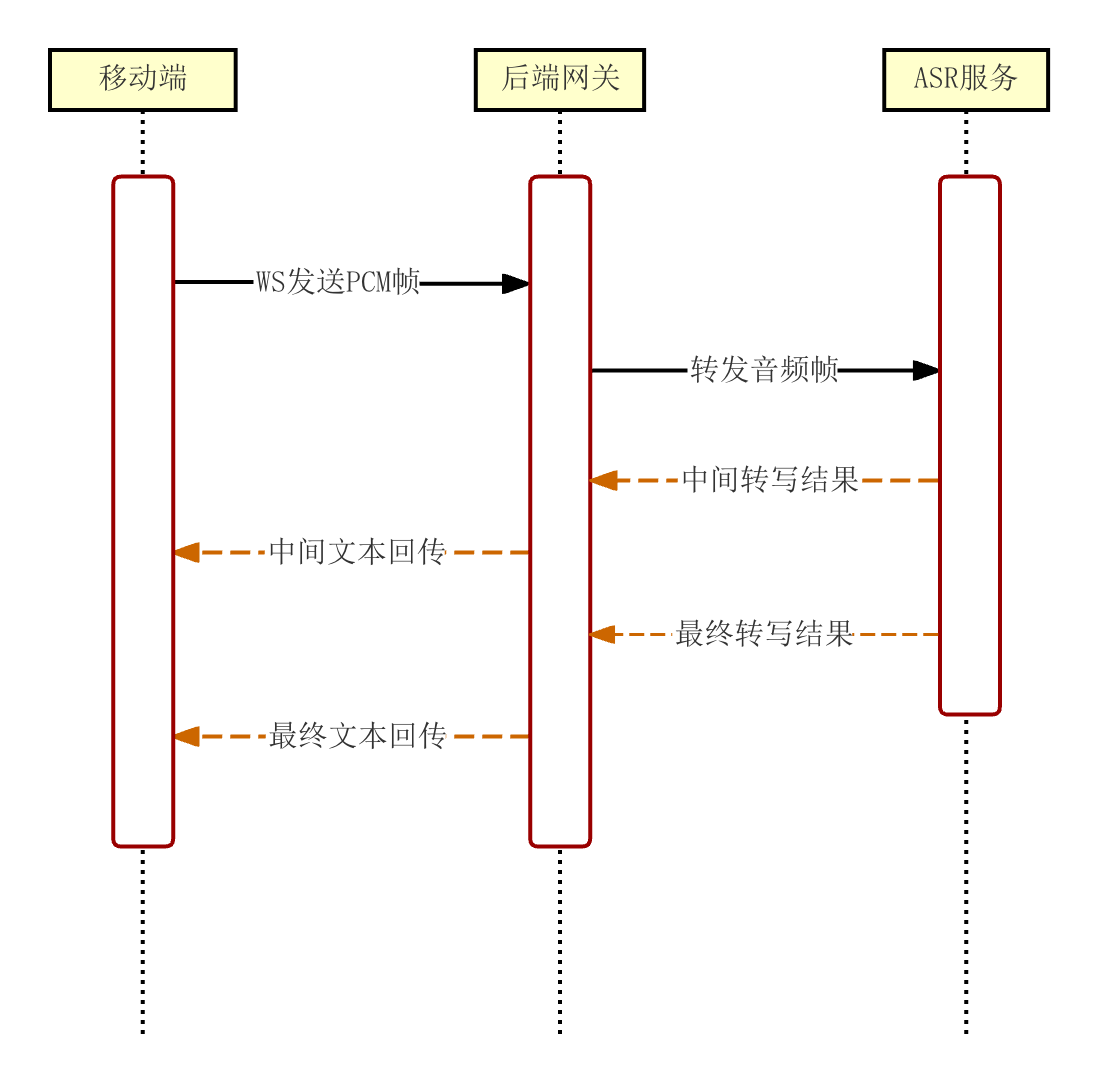
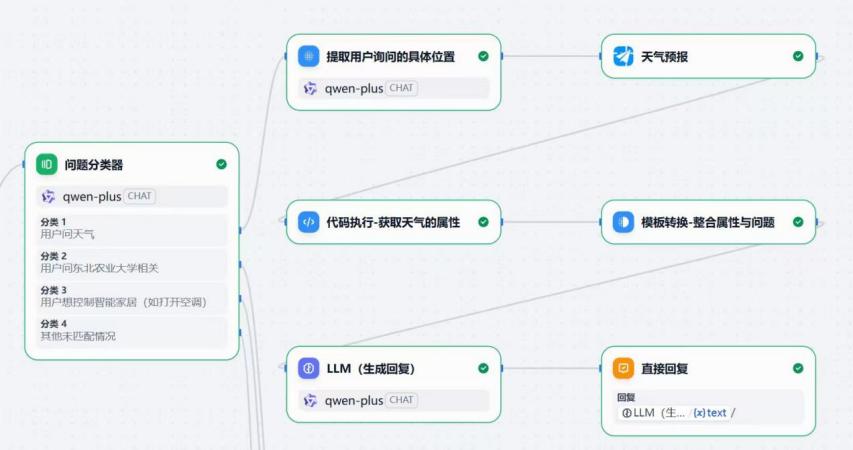
Dify 负责意图分类与工具编排。天气、校务、设备控制使用统一输入输出格式,前端展示与语音播报不需要为每个分支单独适配。
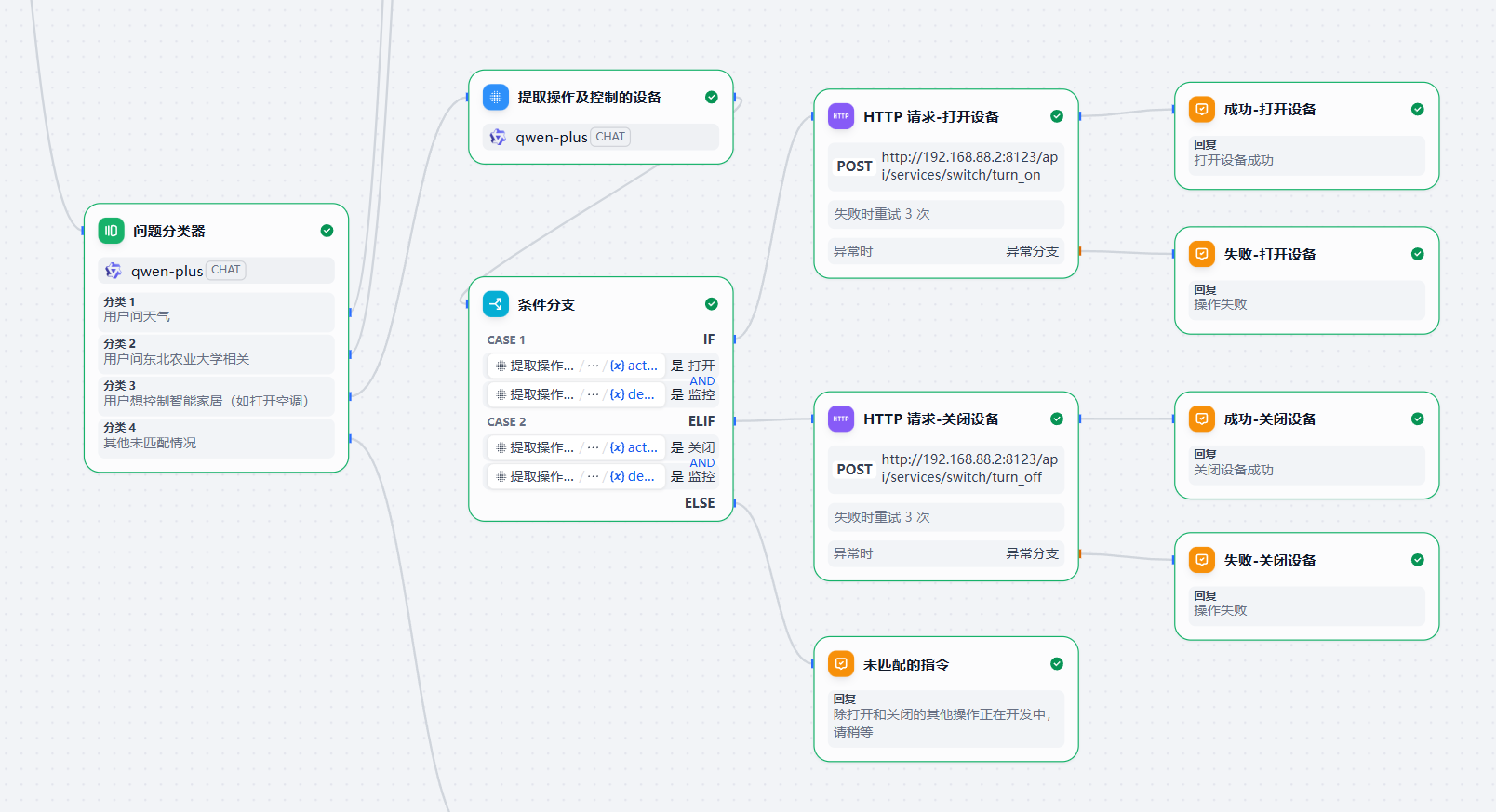
系统工作逻辑主要在 Dify 工作流中实现,流程分为语义分析、任务打包和分支跳转三部分。系统先判断用户问题属于天气、校务还是设备控制,再进入对应分支处理。
各节点之间采用结构化参数传递,分类节点只检测意图,执行节点只调用业务能力,汇总节点只整合结果。这样后续增加新业务时,只需扩展分类条件和分支节点,不必大改主流程。
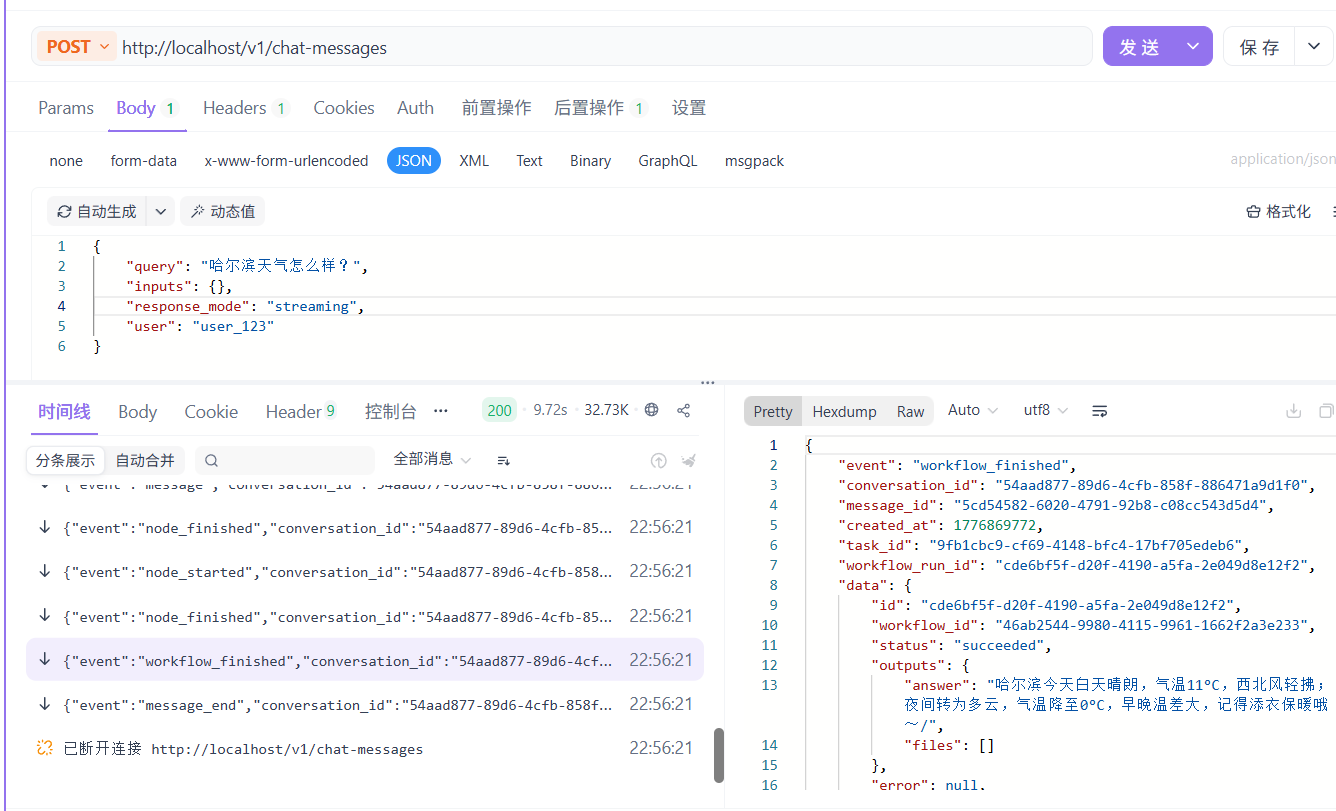
天气分支从用户句子中抽取地点、日期或时间段,先做参数规范化与合法性校验,再调用高德天气 API,并把接口字段整理成便于显示和播报的自然语言。
该分支会先把口语化问题转换成接口可接受的结构化参数,调用前检查参数是否缺失、时间范围是否合法,调用后再检查返回值完整性,避免把半成品数据展示给用户。
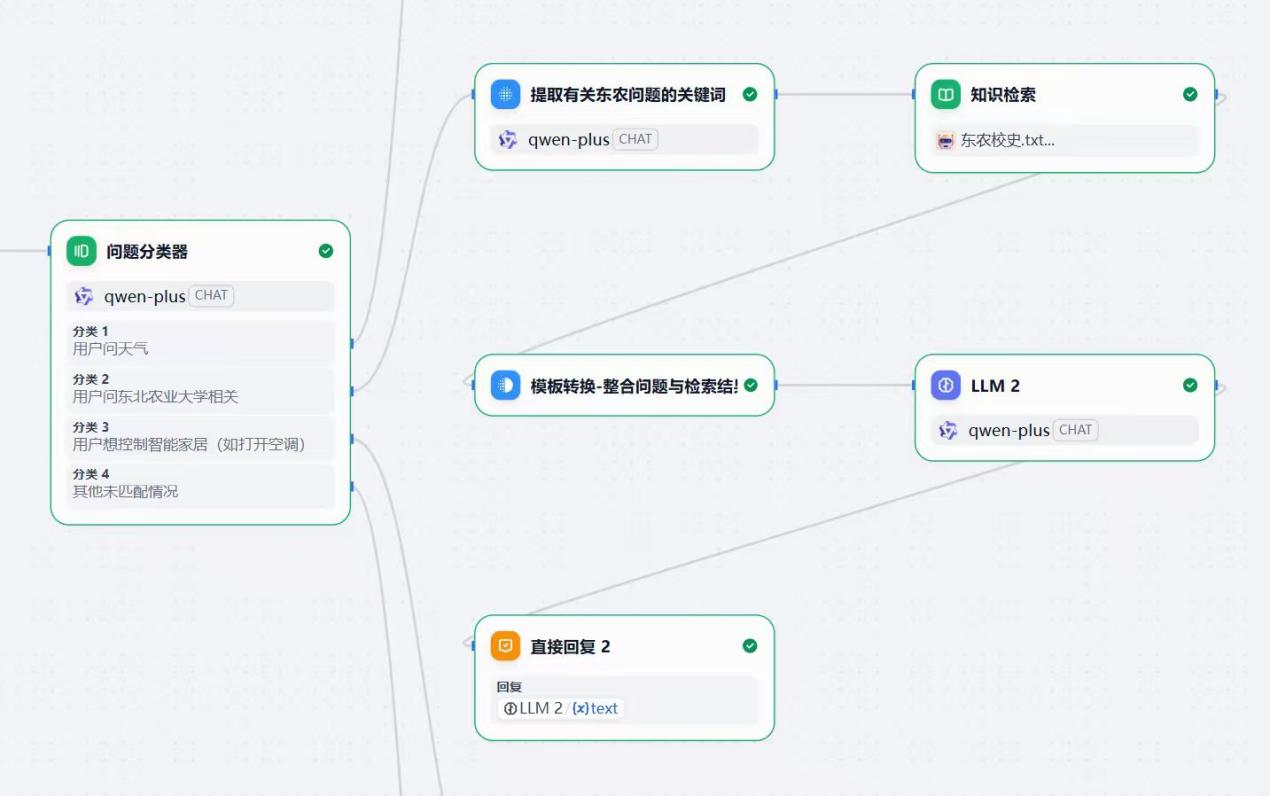
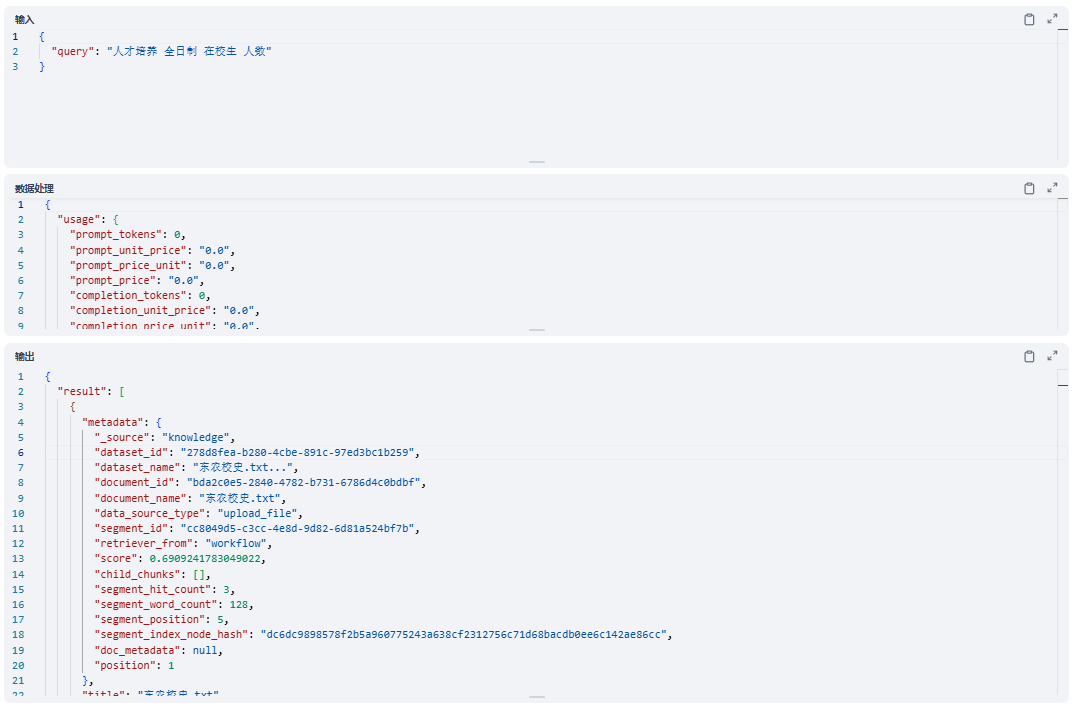
校务分支先在东北农业大学相关知识库中检索候选片段,再进行排序、过滤和总结,要求回答有来源依据;当信息不足时避免编造,保证校务咨询的可信度。
该部分与天气查询、设备控制使用相同的框架,但针对校园校务内容做了特有调整。答案按重要性递减组织,先给出核心信息,再补充相关说明,便于手机端展示和语音播报。
设备分支识别对象、动作和参数,再映射为 Home Assistant 的服务调用;执行后把设备状态、提示文本和语音播报统一回传。
设备控制的关键,是把用户口语化操作指令转化为设备能理解的操作。系统会识别设备实体、动作和可选参数,发送命令前检查权限与设备可用状态,执行后监听最新状态。
CosyVoice 将业务结果分段合成为音频,前端使用 createInnerAudioContext 管理播放队列、会话绑定与打断逻辑。
文本转语音模块把系统最终生成的业务回复转化为可听的声音文件。系统采用分段流式合成,前端不必等待整段音频全部生成,一旦收到第一段音频即可开始播放。
播放控制模块会保存待播放、正在播放、暂停和任务切换等状态。若数字人正在播报时用户发送新请求,前端会立即停止当前音频并清空旧队列,保证用户听到的是最新请求的结果。